Machine Learning for Design
Lecture 6
Natural Language Processing - Part 2
Previously on ML4D
Machine Learning: Observe pattern of features and attempt to imitate it in some way

- A feature is an individual measurable property or characteristic of a phenomenon
- Choosing informative, discriminating, and independent features is essential for a well-working ML
- Features
- Images —> pixel values (e.g. B/W, RGB)
- Numbers —> OK
- What about text?
Textual Documents
- A sequence of alphanumerical characters
- Short: e.g. tweets
- Long: e.g Web documents, interview transcripts
- Features are (set of) words
- Words are also syntactically and semantically organised
- Feature values are (sets of) words occurrences
- Dimensionality —> at least dictionary size

Main types of NLP Tasks
- Label (classify) a region of text
- e.g. part-of-speech tagging, sentiment classification, or named-entity recognition
- Link two or more regions of text
- e.g. coreference
- are two mentions of a real-world thing (e.g. a person, place) in fact referencing the same real-world thing?
- e.g. coreference
- Fill in missing information (missing words) based on context
Language Representation
Language = vocabulary and its usage in a specific context captured by textual data
What is a language model?
- A collection of statistics learned over a particular language
- Almost always empirically derived from a text corpora
What are language models used for?
Measure how important (or descriptive) a word is in a given document collection
e.g., find the set of words that best describe multiple clusters (see Assignment 2)Predict how likely a sequence of words is to occur in a given context
e.g., find the words that are more likely to occur next
What is the issue with word representation?
- Words are discrete symbols
- Machine-learning algorithms cannot process symbolic information as it is
- We need to transform the text into numbers
- But we also need a way to express relationships between words!
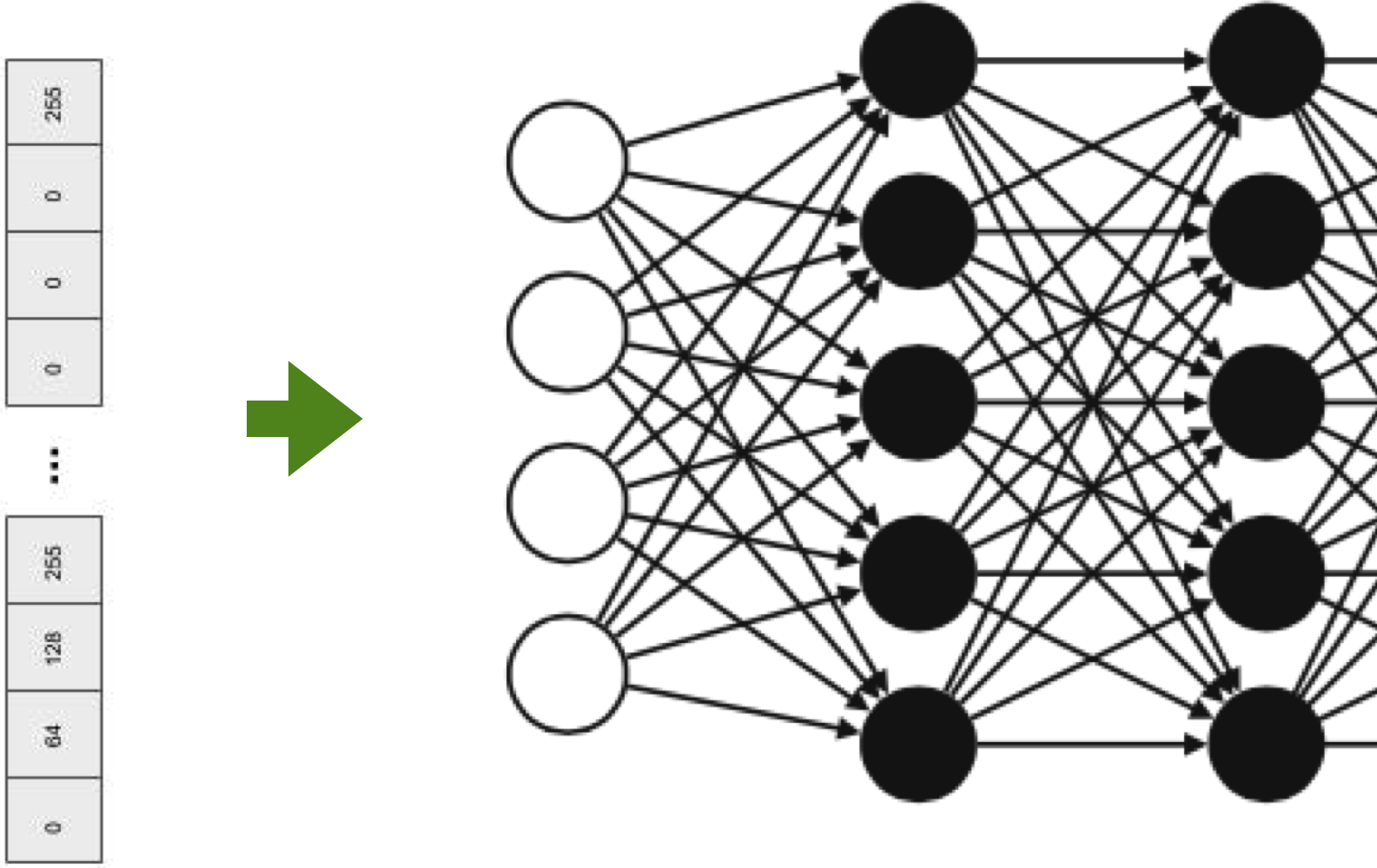
A simple approach
- Assign an incremental number to each word
- Problem: there is no notion of similarity
- Is a cat as semantically close (similar) to a dog as a dog is to a pizza
- Also, no arithmetic operations
- Does it make sense to calculate to establish similarity?
Word Embeddings
- Embed (&represent&) words in a numerical n-dimensional space
- Essential for using machine learning approaches to solve NLP tasks
- They bridge the symbolic (discrete) world of words with the numerical (continuous) world of machine learning models
Approach 1
Assign numbers to words, and put semantically related words close to each other
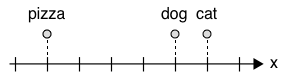
- We can now express that is more related to than to
- But is more related to than to ?
Approach 2
Assign multiple numbers (a vector) to words
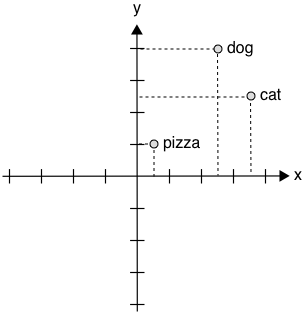
- We can calculate distance (and similarity)
- e.g. Euclidean, or Cosine (angles)
- But what is the meaning of an axis?
One-Hot Encoding
- Each word in the vocabulary is represented by a one-bit position in a HUGE (sparse) vector
- Vector dimension = size of the dictionary
- There are an estimated 13 million tokens for the English language
- Problems with one-hot encoding:
- The size of the vector can be huge
- Do you Remember Zip’s law?
- Easy to reach words
- But we can use stemming, lemmatisation, etc
- The size of the vector can be huge
- Still, no notion of similarity or words relationship
- Each word is an independent, discrete entity
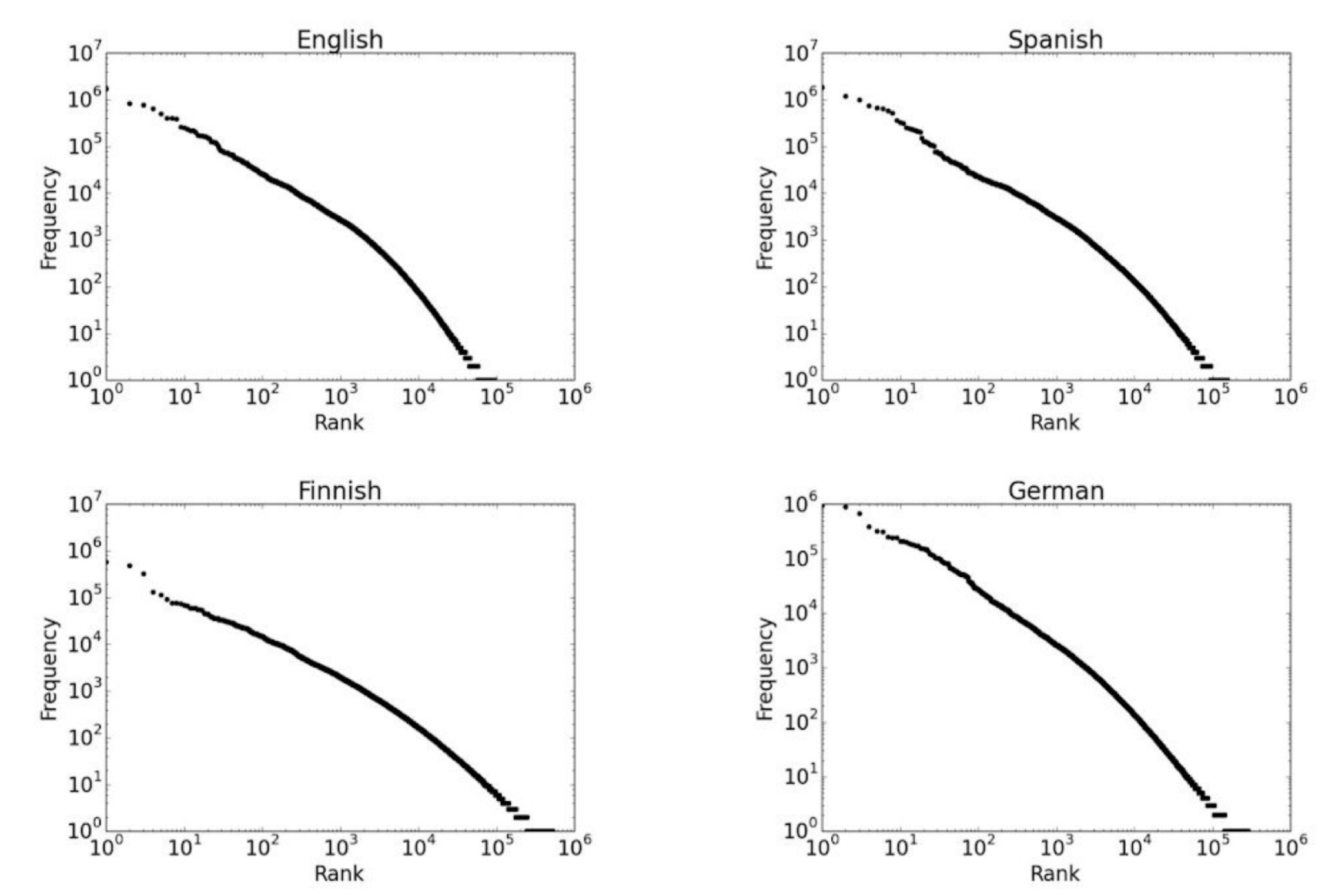
Independent and identically distributed words assumption
- The simplest language models assume that each word in a text appears independently of the others
- The text is modeled as generated by a sequence of independent events
- The probability of a word can be estimated as the number of times a word appears in a text corpus
- But high probability does not mean important (or descriptive)
Back to the term-document matrix
- How to measure the importance of words?
Term frequency
Raw frequency
Log normalisation
Normalised Frequency
- Measuring the importance of a word to a document
- The more frequent the word, the more important it is to describe the document
Inverse document frequency
- Measuring the importance of a word to a document collection
- Rare terms are more important than common terms
- Scaling a word’s importance (in a document) based on both its frequency and its importance in the collection
N-gram language models
N-gram language models
- Calculate the conditional probabilities among adjacent words
- Given the word , what is the probability of the next word
- e.g., given , vs.
- bi-grams --> 2 words, 3-grams --> 3 words
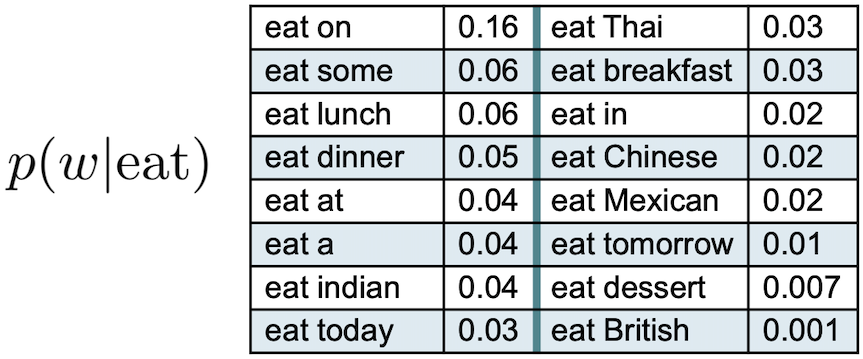
N-gram language models
- More accurate
- The probabilities depend on the considered context
- The model accuracy increases with N
- The syntactic/semantic contexts are better modeled
- Grammatical rules
- e.g., an adjective is likely to be followed by a noun
- Semantic restrictions
- e.g., Eat a pear vs. Eat a crowbar
- Cultural restrictions
- e.g., Eat a cat
Limits of N-grams-based Language Model
- Conditional probabilities are difficult to estimate
- For dictionary contains terms there are N-grams (30K words, 900M bi-grams)
- the corpus should be billions of documents big for a good estimation
- For dictionary contains terms there are N-grams (30K words, 900M bi-grams)
- They do not generalize to unseen words sequences
Representing words by their contexts
- Distributional semantics: A word’s meaning is given by the words that frequently appear close-by
- When a word appears in a text, its context is the set of words that appear nearby (within a fixed-size window)
- The contexts in which a word appears tell us much about its meaning
“You shall know a word by the company it keeps” - The distributional hypothesis, John Firth (1957)
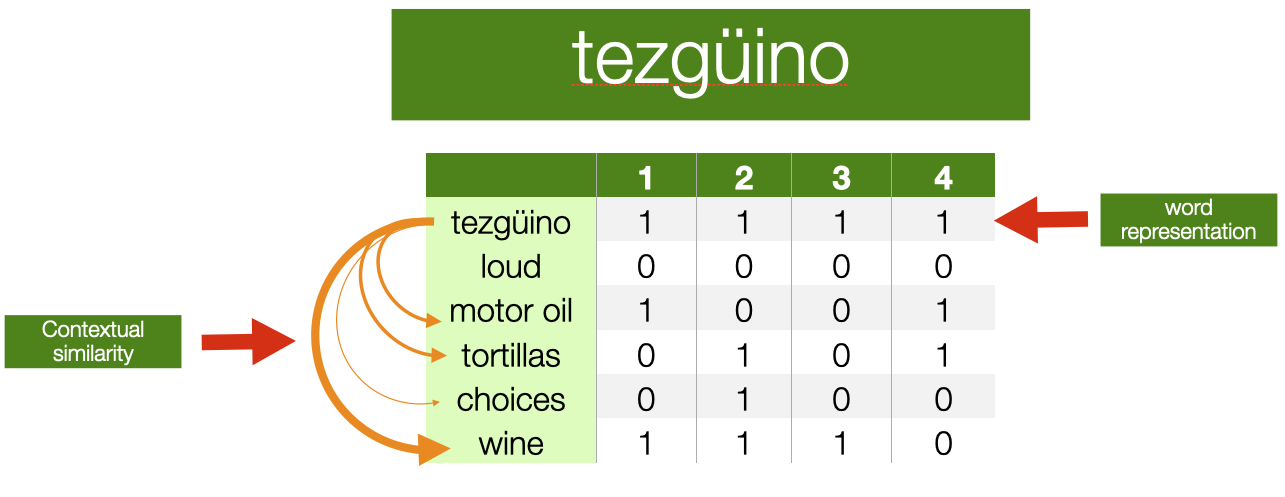
- What other words fit into these contexts?
- Contexts
- 1 A bottle of ___ is on the table
- 2 Everybody likes ___
- 3 Don’t have ___ before you drive
- 4 We make ___ out of corn
Distributional Word Embeddings
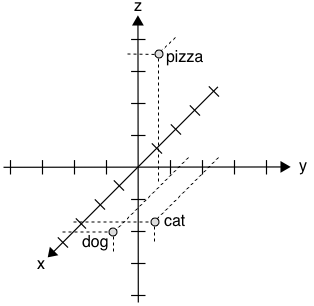
- Define dimensions that allow expressing a context
- The vector for any particular word captures how strongly it is associated with each context
- For instance, in a -dimensional space, the axis could have the semantic meaning
- -axis represents some concept of "animal-ness"
- -axis corresponds to "food-ness"
Distributional Word Embeddings
- Defining the axes is difficult
- How many?
- A lot less than the size of the dictionary (dense vectors)
- But at least ~100-dimensional, to be effective
- GPT-2 has 768, ChatGPT 12,288
- How many?
- How to assign values associated with the vectors?
- Tens of millions of numbers to tweak
How to calculate Word Embeddings?
- With machine learning models
- Advanced topic
- Wait for Advanced Machine Learning for Design :)
Ok, just a sneak peak
- SKIPGRAM: Predict the probability of context words from a centre word
- Input: one-hot vector of the centre word
- the size of the vocabulary
- Output: one-hot vector of the output words
- the probability that the output word is selected to be in the context window
- Embeddings: lower-dimensional representation of context of co-occurence
Using Word Embeddings
How can embeddings be used with NLP Models?
- Word embeddings are trained from a corpus
- And then they can be reused!
- 3 scenarios
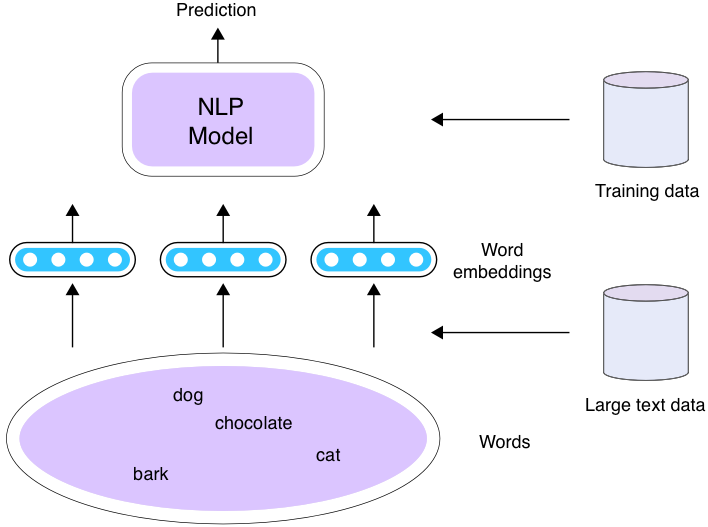
Scenario 1
- Train word embeddings and your model at the same time using the train set for the task
Scenario 2: Fine-Tuning
- Initialise the model using the pre-trained word embeddings
- e.g., train on Wikipedia, or large Web corpora
- Keep the embedding fixed while training the model for the task
- Another example of transfer learning
Scenario 3: Adaptation
- The embeddings are adapted while the downstream model is trained, the train set for the task
- Same as Scenario 2, but the embeddings are now more close to the words distribution in your training set
Evaluating Word Embeddings
How to evaluate word vectors?
- Intrinsic: evaluation on a specific/intermediate subtask (e.g. analogy)
- Fast to compute
- It helps to understand that system
- Not clear if helpful unless correlation to the actual task is established
- Fast to compute
- Extrinsic: evaluation of a real task
- It can take a long time to compute the accuracy
- Unclear if the subsystem is the problem or if it is an interaction with other subsystems
Intrinsic evaluation
Word vector analogies
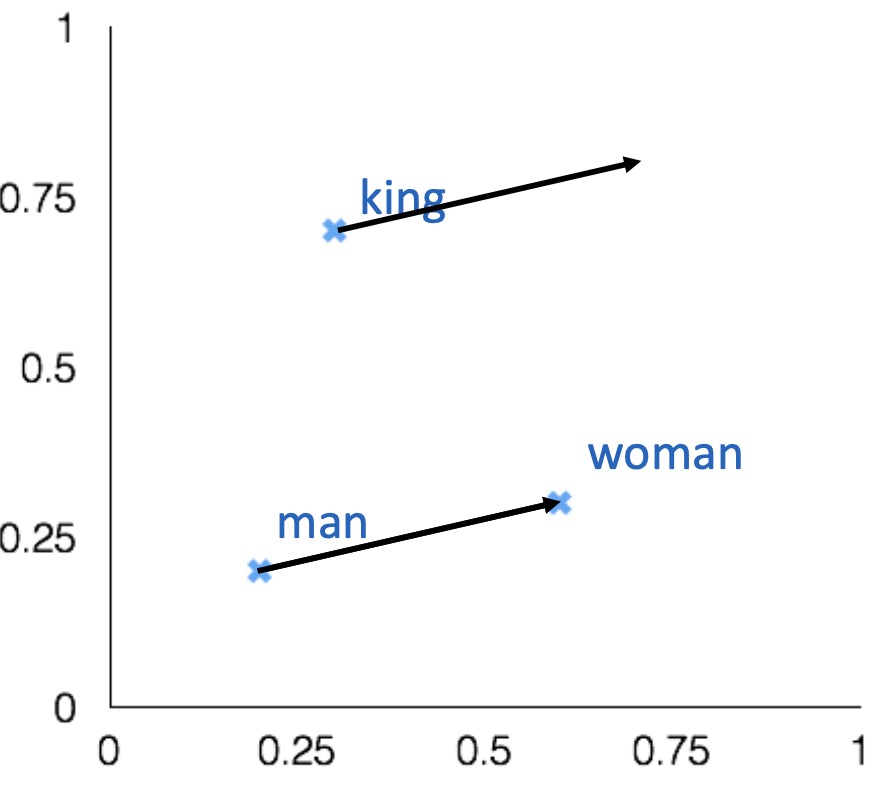
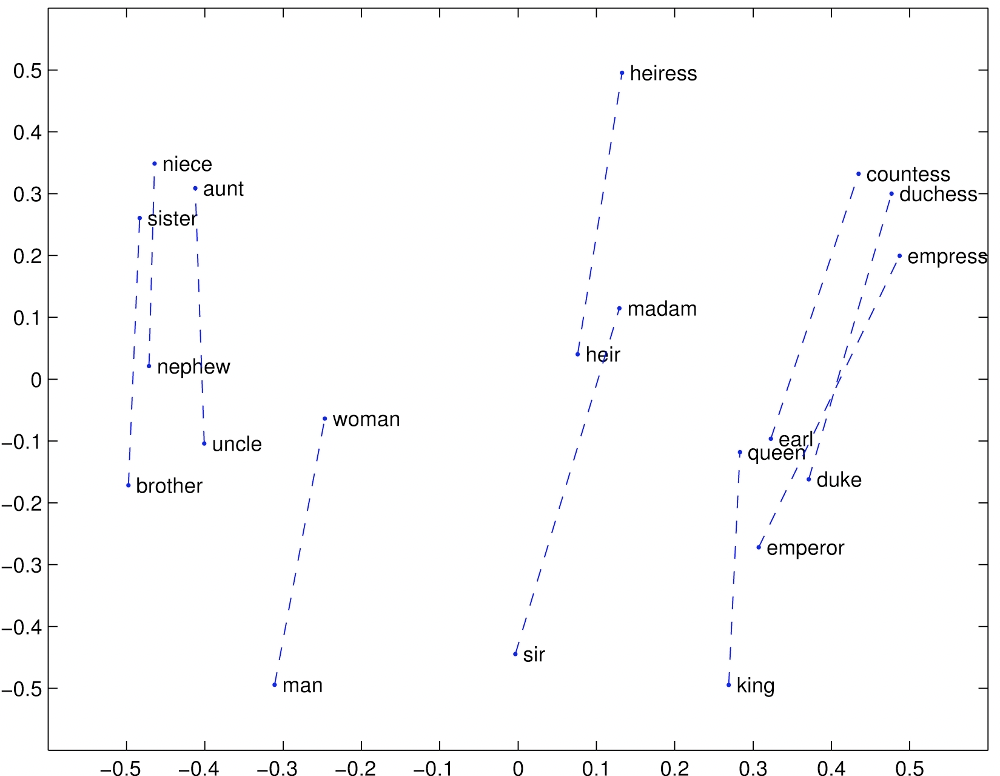
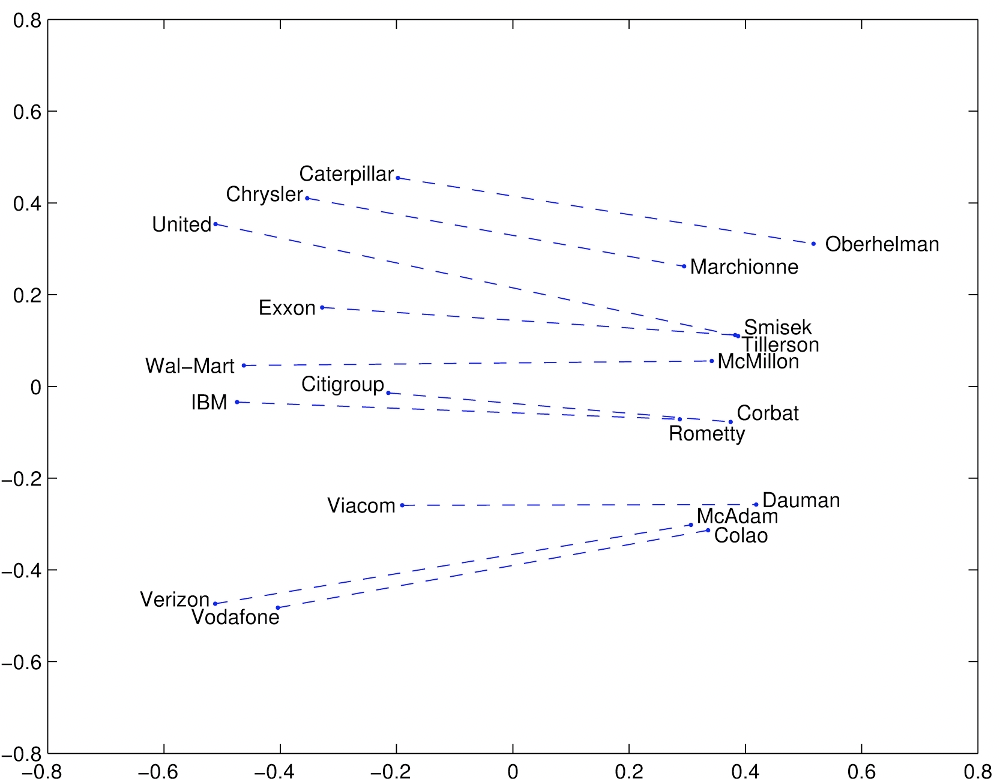
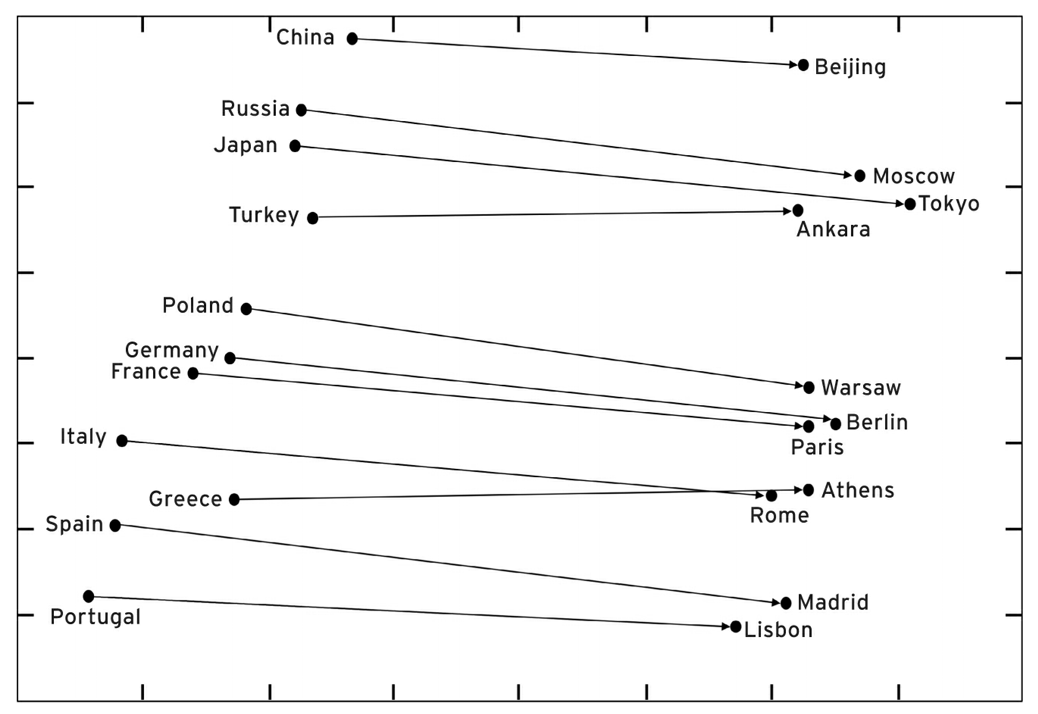
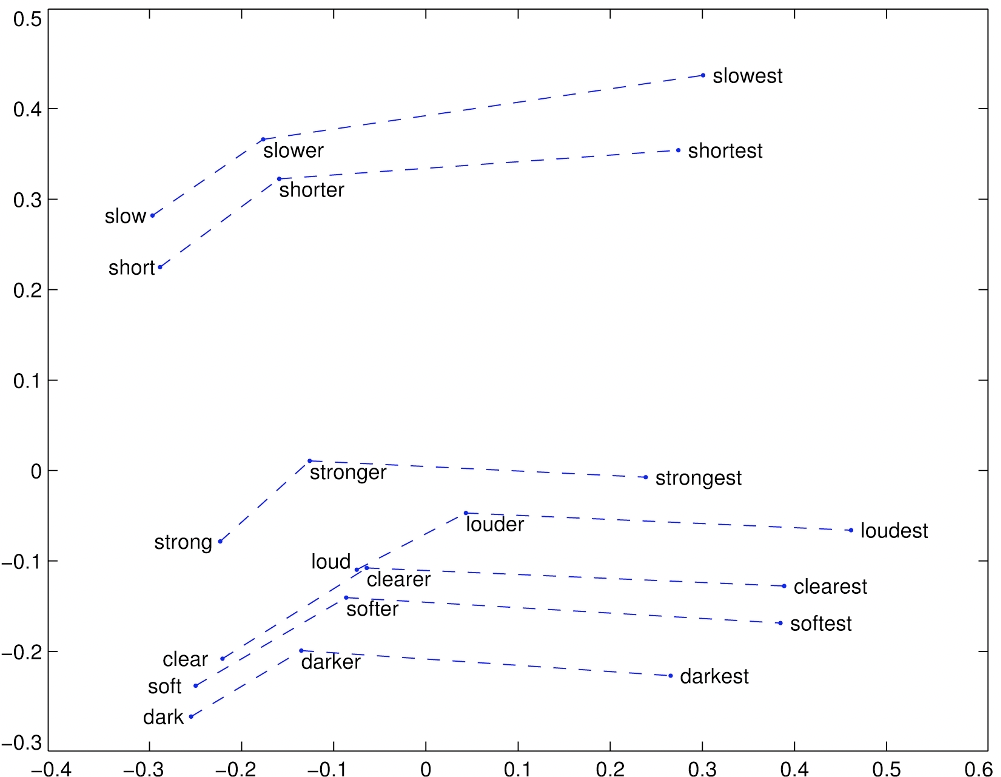
Intrinsic evaluation
- Find a word such that the vector is closest (cosine similarity) to
- Correct if the word found is
- Can be applied to test for syntactic analogy as well
Gender relation
Company - CEO
Countries and their capital
Comparatives and Superlatives
There are problems, of course
- By exploring the semantic space, you can also find analogies like
- is to as is to
- is to as is to
Biases in word vectors might leak through to produce unexpected, hard-to-predict biases
- is to as is to ______
- is to as is to ______
- is to as is to ______
- is to as is to ______
- is to as is to homemaker
- is to as is to mechanical engineer
- is to as is to muse
- is to as is to geniuses
Machine Learning for Design
Lecture 6
Natural Language Processing - Part 2
Credits
CIS 419/519 Applied Machine Learning. Eric Eaton, Dinesh Jayaraman. https://www.seas.upenn.edu/~cis519/spring2020/
EECS498: Conversational AI. Kevin Leach. https://dijkstra.eecs.umich.edu/eecs498/
CS 4650/7650: Natural Language Processing. Diyi Yang. https://www.cc.gatech.edu/classes/AY2020/cs7650_spring/
Natural Language Processing. Alan W Black and David Mortensen. http://demo.clab.cs.cmu.edu/NLP/
IN4325 Information Retrieval. Jie Yang.
Speech and Language Processing, An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. Third Edition. Daniel Jurafsky, James H. Martin.
Natural Language Processing, Jacob Eisenstein, 2018.