Preparation
Table of contents
This section prepares you for the module using image classification tasks. We will give you a hypothetical scenario about the requirement of building a product-service system to identify trash bins in cities using image processing.
Suppose you work with the city of Amsterdam to design an effective trash collection service. In order to design the service, the municipality must know where all the trash bins in the city are. Actually, the Amsterdam municipality knows where all the containers are, but this is not common for all cities in the world. More information about the location of trash bins in Amsterdam is in the following:
- Trash bin locations: https://kaart.amsterdam.nl/afvalcontainers
Your task is to design and build an application that is able to recognize a trash bin from images collected by the scan cars traveling around the city. In this way, the city can then calculate the location of trash bins. More information about the scan cars is in the following:
To build the trash bin recognition application, we will use a pre-trained machine learning model hosted on Hugging Face. Hugging Face is an online service where pre-trained machine learning models are hosted and made available for use. A “pre-trained” model means that someone already trained the model using some datasets (could be very large) to find useful parameters. Modern models can be hard to train in terms of the amount of needed data and computation resources. The benefit of using a pre-trained model is that the hard work is done by someone else. So, you save time collecting a large dataset to train the model.
Machine learning models have many parameters that represent the distribution of the data. For example, think about a regression model y=mx+b where y and x represent blood pressure and age, respectively. In this case, m and b are the parameters of the model that represent the slope and interception. Typically, parameters in the machine learning models are initialized using random numbers. And “training” a model means finding the parameters that make the model fit the data well. Using the regression model that we mentioned before as an example, training the model means that we want to find a good pair of m and b that makes the model predict blood pressure from age reasonably well.
Before attending the tutorial, complete the tasks listed in the following subsections. We will discuss the results at the beginning of the tutorial session.
Task 1
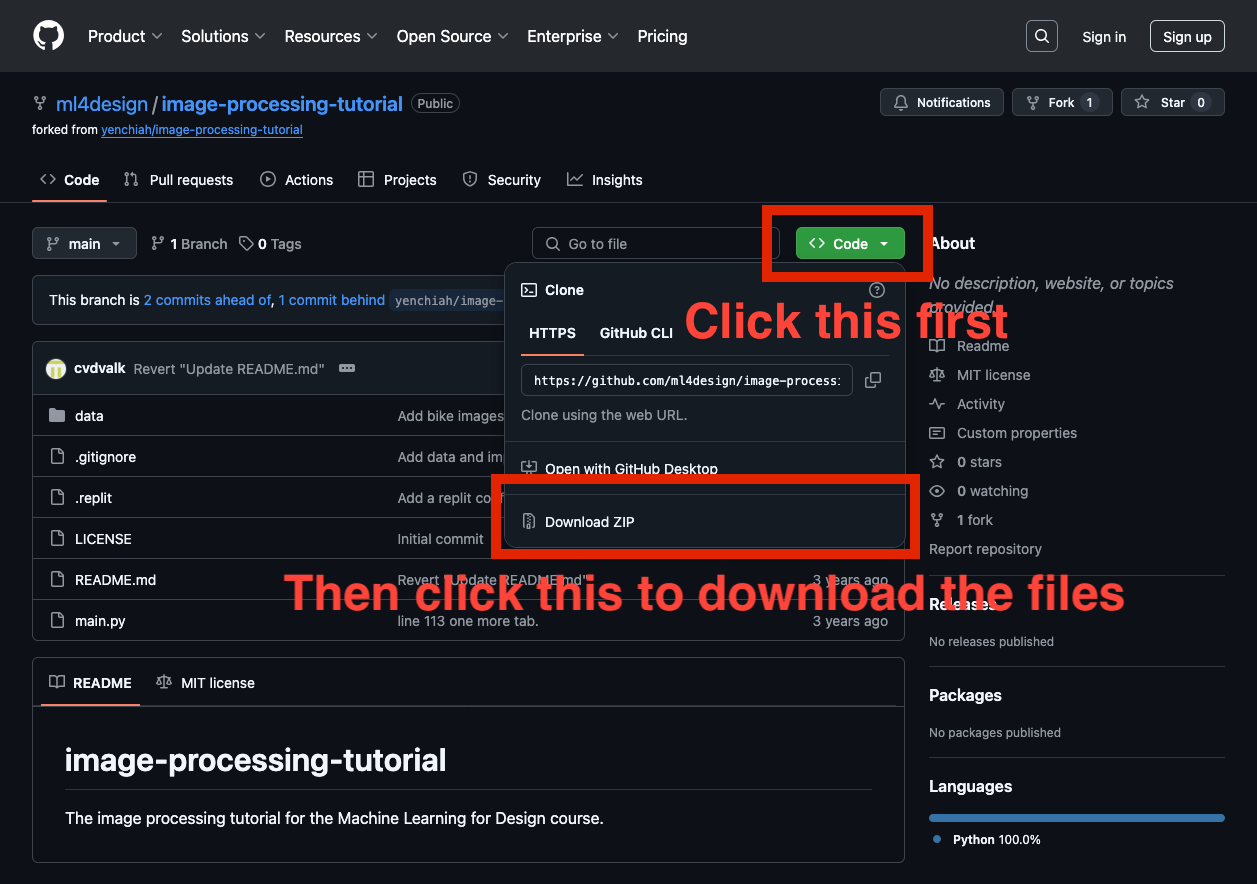
In this task, we will help you familiarize yourself with the Hugging Face tool. First, download the trash bin images from the link below on GitHub. The GitHub platform is a service for hosting code and data, largely used by the open-source community.
- Link to code and images: https://github.com/ml4design/image-processing-tutorial
Second, go to the link below that contains a deployed machine learning model.
- Link to the model: https://huggingface.co/google/vit-base-patch16-224
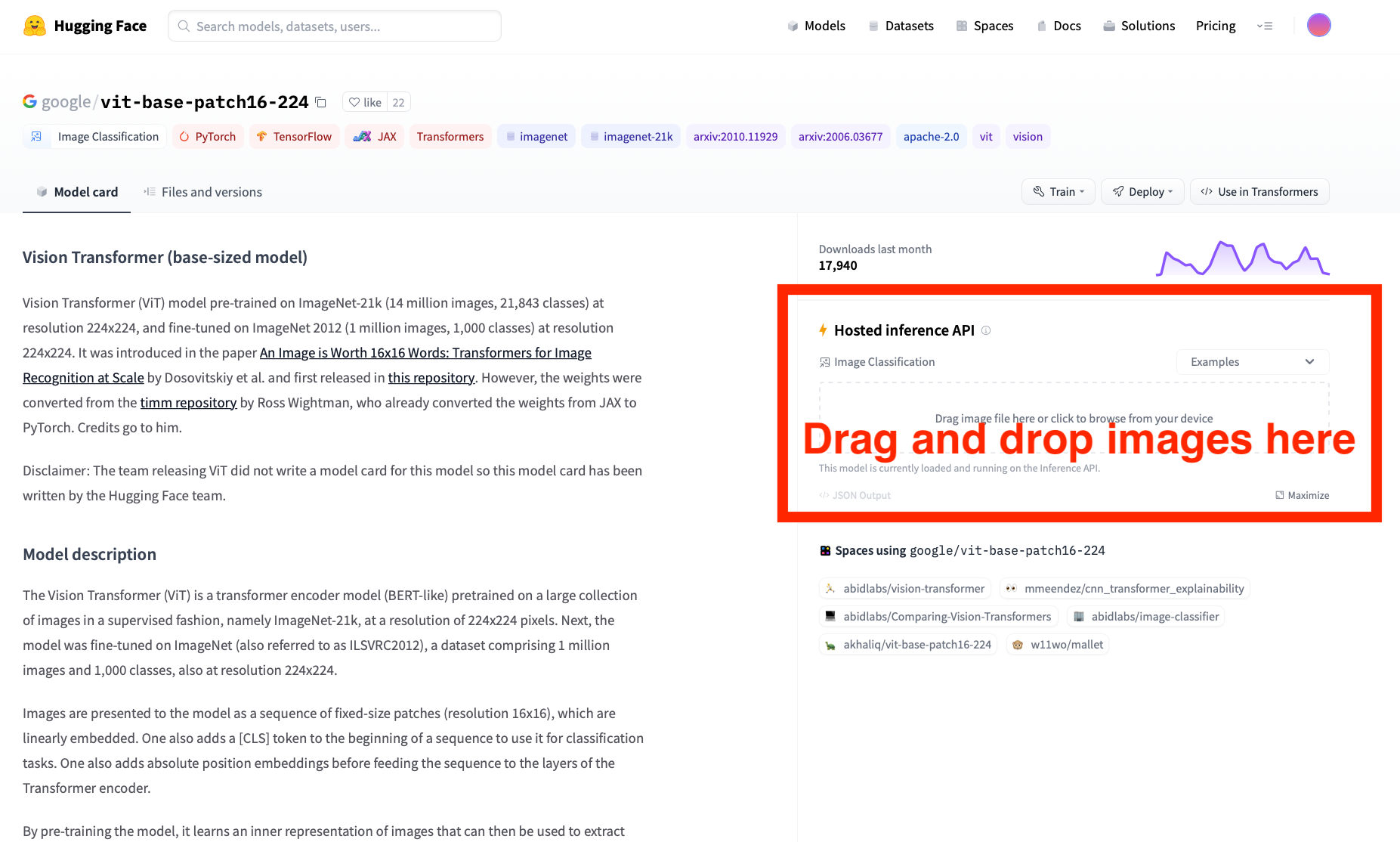
Next, use the web interface to classify one trash bin image in the “data/trash-bin/1/” folder that you just downloaded. You can use any image in the folder. Please DO NOT use the images in the “data/trash-bin/2/” folder for this task. Drag and drop the image to the area on the web interface, as shown in the following screenshot.
The model that we just used is called Vision Transformer. It is a state-of-the-art model that takes images as input, and outputs the objects contained in the images - at least the ones recognized by the model. More information about the model is on the left side of the web page that we mentioned above.
After you drag and drop the image into the web interface, check the predictions from the model, as shown in the following screenshot.
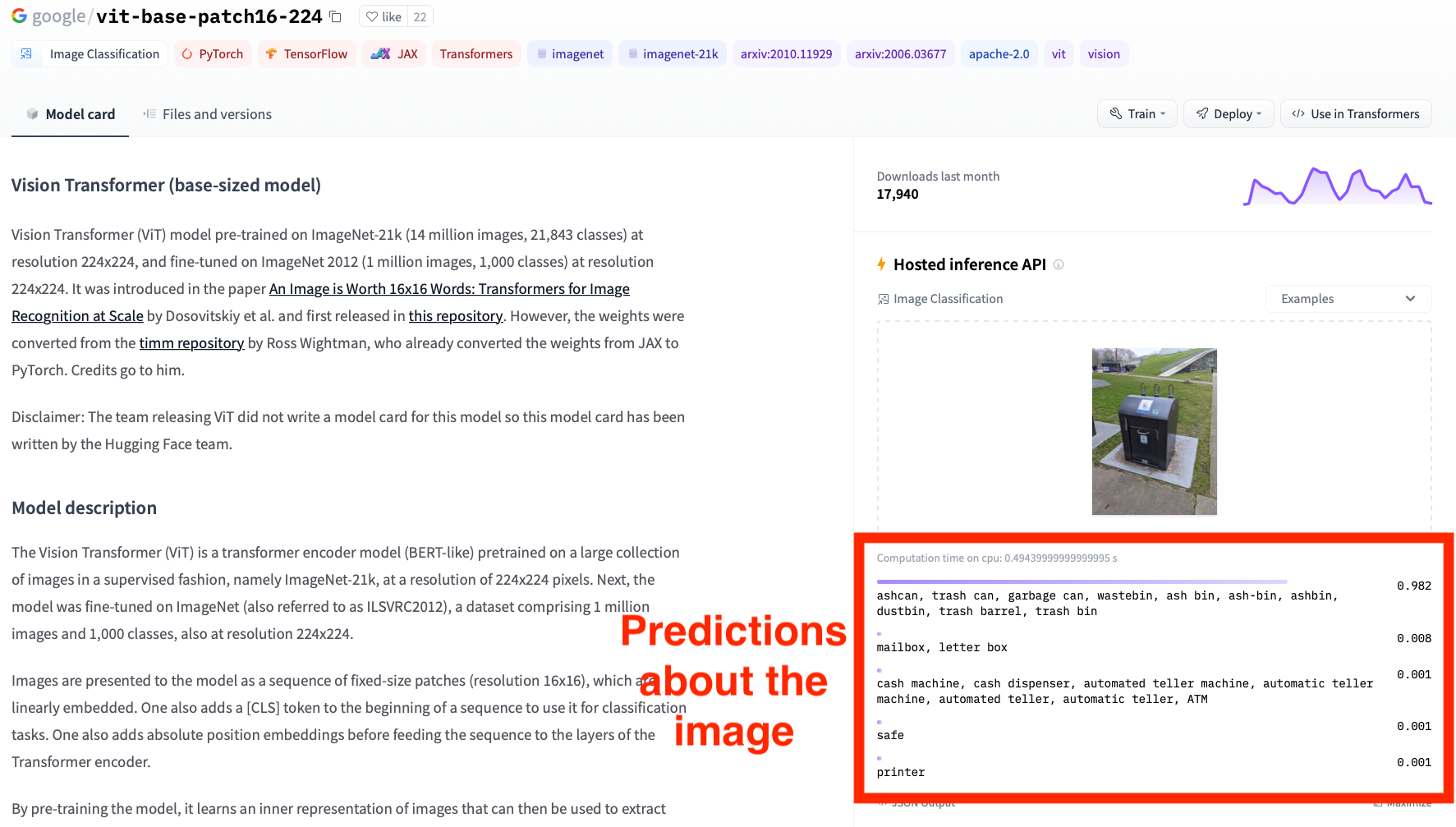
The output from the model has five predictions with corresponding numbers, which means the top five predictions. The numbers are probabilities, which indicates how confident the model is about the prediction, with 1 being the highest confidence and 0 being the lowest confidence. For example, in the above screenshot, the model predicts that the image has a trash bin with a 0.982 probability, which is very high.
To familiarize yourself with the web interface, repeat the above steps to use the Vision Transformer model to predict at least five images in the “data/trash-bin/1/” folder.
Task 2
In this task, you will use a different set of trash bin images (other than the set that you used in the previous task) and reflect on the model predictions. First, use the same model that we mentioned in the previous task to classify trash bin images in the “data/trash-bin/2/” folder. You need to try ALL images in this folder and check the model outputs (i.e., the predictions) on the web interface.
Next, write down what you observe. Is the model making correct predictions with reasonable probability? If not (e.g., wrong prediction or low probability), think about why it is not working well and write them down. While thinking, consider the following aspects:
- The proportion of the trash bin relative to the size of the entire image. What will happen if the trash bin is very small in the image?
- The appearance of the trash bin. Keep in mind that the model is pre-trained on some other datasets. Think about what will happen if the trash bin does not appear in the dataset that was used to train the model?
- The position of the trash bin relative to other objects in the image. What will happen if the trash bin is behind something?
Task 3
In this task, you will use an alternative pre-trained model to process the trash bin images. First, go to the following page with a different deployed model:
- Link to another model: https://huggingface.co/microsoft/resnet-50
Then, use the web interface to again classify ALL images in the”data/trash-bin/2/” folder. Check the outputs from this alternative model. Like the previous task, write down what you observe, considering the aspects that were mentioned in the previous task. Pay specific attention to the images that work on only one of the models or do not work on both models.
Task 4
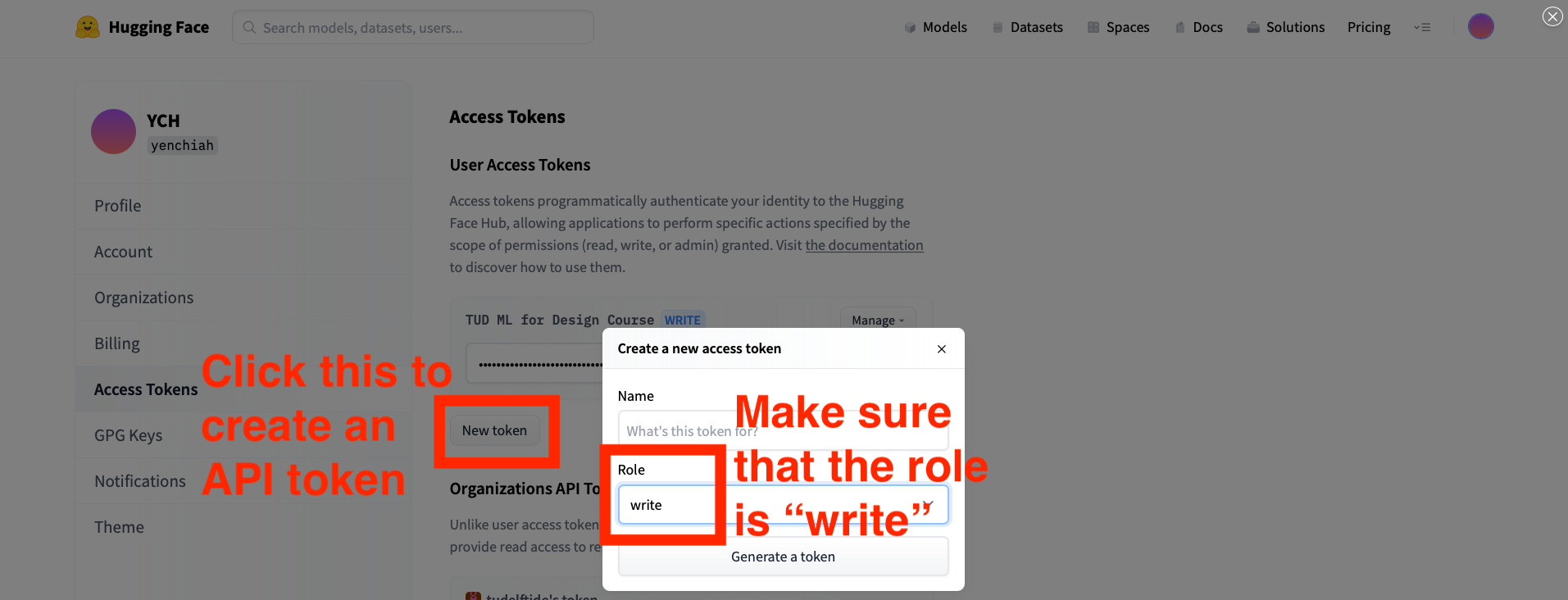
Finally, you need to register a Hugging Face account and obtain the API token to use the machine learning models. API means the Application Programming Interface, which allows computer programs to talk to each other. And the API token is used for authentication. You must do this before the tutorial since we need the API token for the tutorial, and it can take more than an hour to have your email confirmed and get the API token. If you do not have the API token before attending the tutorial session, it is highly likely that you will not be able to follow the tutorial content.
First, go to the following page to register a Hugging Face account. If you already have a Hugging Face account, you can skip this step.
- Link to register a Hugging Face account: https://huggingface.co/join
Then, check and wait for a confirmation email from Hugging Face. You need to confirm your email address to be able to get an API token. After you confirm your email address on Hugging Face, go to the following link to create an API token.
- Link to create an API token: https://huggingface.co/settings/token