Preparation
Table of contents
In the next three Tasks, we will help you familiarize yourself with some simple text-processing techniques. Remember that for each task, it is important to reflect on the advantages and disadvantages of such techniques.
A short introduction to Voyant
This section prepares you for the text-processing tutorial. As a designer, you are often faced with the task of analyzing large collections of textual data towards gaining an improved understanding of people’s opinions and experiences. Occasionally, you might not know what you are looking for. Instead, you need to go through the textual data and explore potential emerging patterns. What are people talking about most often? How do they feel about their experience with a product, service, or system they used?
In tasks 1-3 we learn how to easily analyze a collection of texts. This tool allows you to understand the content of the collection without a lot of preparation. But keep in mind! Everything comes at a cost. With relative ease, you lose the opportunity to obtain deeper insights and tailor the tool for your needs.
We would like you to use a web-based reading and analysis environment for digital texts called voyant (https://voyant-tools.org) to explore different types of texts. When you go to the voyant web page you will see a box where you could type in text or the url of another website. Additionally, it has an “upload” button which you could use to upload a document you already have.

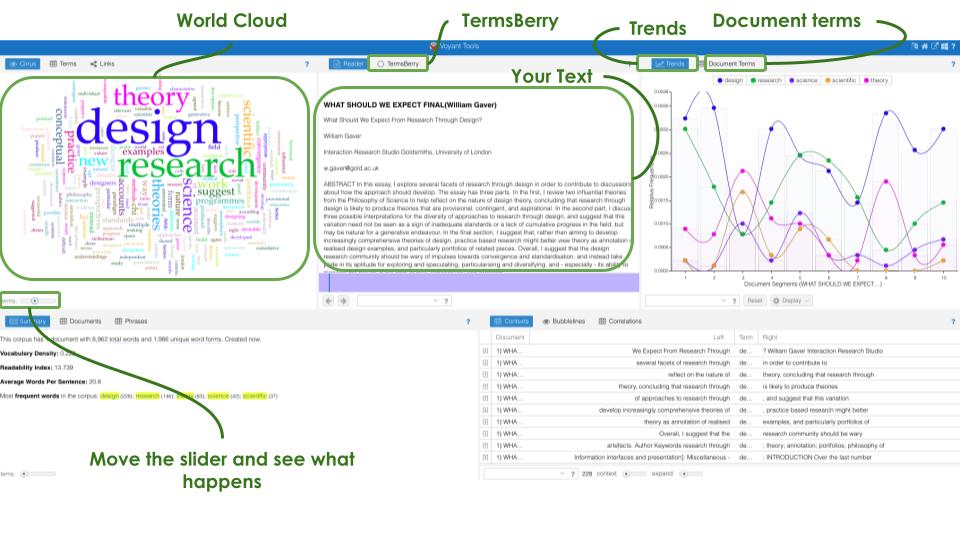
When you press “Reveal” you will see how your text is analyzed. In the middle, you can see the whole text that is being analyzed. On the top of your text, there is a button called TermsBerry. The TermsBerry tool provides a way of exploring high frequency terms and their collocates (words that occur in proximity).
On the left, you will see a word cloud. A world cloud is a visual representation of words that give greater prominence to words that appear more frequently. Below the word cloud, there is a slider named “Terms” which you can set to the number of words you want to include in your world cloud. On the right, you can see the Trends of the different words included in your text. Trends is a visualization that represents the frequencies of terms across documents in a corpus or across segments in a document, depending on the mode. If you press the button next to the “Trends” named “Document Terms” you will see how many times each word occurs in your text.
Task 1
Go to https://voyant-tools.org and load the following text:
| “In this essay, I explore several facets of research through design in order to contribute to discussions about how the approach should develop. The essay has three parts. In the first, I review two influential theories from the Philosophy of Science to help reflect on the nature of design theory, concluding that research through design is likely to produce theories that are provisional, contingent, and aspirational. In the second part, I discuss three possible interpretations for the diversity of approaches to research through design, and suggest that this variation need not be seen as a sign of inadequate standards or a lack of cumulative progress in the field, but may be natural for a generative endeavour. In the final section, I suggest that, rather than aiming to develop increasingly comprehensive theories of design, practice based research might better view theory as annotation of realised design examples, and particularly portfolios of related pieces. Overall, I suggest that the design research community should be wary of impulses towards convergence and standardisation, and instead take pride in its aptitude for exploring and speculating, particularising and diversifying, and - especially - its ability to manifest the results in the form of new, conceptually rich artefacts.” |
This text is an abstract of a paper you could find here, if you want to experiment you can actually upload the entire paper in Voyant (or any other document you wish to analyze).
Try to understand how the Voyant tool could be useful when you analyze large amounts of textual data. Reflect on the following:
- How do word clouds help you to get a quick idea of the subject of the text? How do you understand it?
- How do links help you to understand a collection’s content?
- How do trends help you to understand a collection’s content?
- What limitations do you see in such a tool? What else would you like to see there?
Suggestion: Feel free to use your own text sample. It can be a paper you (don’t) want to read, blog post in social media, a couple of tweets. Whatever you find interesting in the form of the text.
Text processing is a complex task. Usually, you work with frequencies of words/phrases and you track the prevalence of particular words/phrases. Sometimes, you’re interested in connections between words/phrases. What you’re looking for depends on your goals and analysis procedure. But here is one crucial step you do regardless of your goals and methods: during text analysis, we work a lot with examples. Meanings of words are contextual, and without finding examples in the text, you risk misunderstanding your findings.
Task 2
Download the document named “task_2.txt” by clicking here.
Upload the document “task_2.txt” on the Voyant tool and press “Reveal”. Look at the results and use the different options you familiarized yourself with, in the previous task. Remember to use the different options offered by the tool (e.g. work cloud, TermsBerry, Document Terms). Try to reflect on the following questions:
- Where do you think this text originates from (e.g. interviews, online forums etc)?
- Is it written by one person or multiple?
- Does the text revolve around a common subject or is it a combination of different completely disconnected subjects?
- Can you name some advantages and disadvantages of analyzing this kind of data using the Voyant tool?
- Open the task_2.txt, read several texts
Task 3
Download the document named “task_3.txt” by clicking here.
Try to answer again the following questions:
- Where do you think this text originates from?
- Is it written by one person or multiple?
- Does the text revolve around a common subject or is it a combination of different completely disconnected subjects? If it’s one subject, which one do you think that is?
- Can you name some advantages and disadvantages of analyzing this kind of data using the Voyant tool?
- Compare the results of the analysis of this document with the previous one. Which one seemed more suitable for this kind of analysis?